Playstation 3 Raytracer
by Robert Flack and Jonathan Ross
Issues porting to the Playstation 3
Before beginning to parallelize and optimize our code for use on the Playstation
3, we needed to port the ray-tracer to be able to compile. Getting the code to
compile on the PPU compiler required the removal of the external libraries in
use as they were not available in the package tree on the playstation.
Writing an image writer
The image writer we were using, libfreeimage++, was not supported by the
playstation 3's libraries. This meant that we had to write our own image writer.
We targeted the simplest image format to write for, and created a bitmap writer.
The header is a simple 54 byte binary code giving depth, width, height and some
more advanced optional bitmap features which we aren't using. The bitmap writer
then simply dumps the raw pixel information (Adding padding after each row of
pixels so that the row is a multiple of 4 bytes long), and we have a usable
image file that we can then view. One complication with moving this over to the
playstation was that it is a PowerPc based architecture, storing values in big
endian, when bitmap expects all of its values to be written in little endian
format. To this end, we wrote a few simple macros to convert the 2 and 4 byte
values between big endian.
#define swap4bytes(data)
\
( (((data) >> 24) &
0x000000FF) | \
(((data) >> 8)
& 0x0000FF00) | \
(((data) << 8)
& 0x00FF0000) | \
(((data) << 24)
& 0xFF000000) )
#define swap2bytes(data)
\
((((data) >> 8)
& 0x00FF) | \
(((data) << 8)
& 0xFF00) )
In order to ensure the code would be backwards compatible, we have a flag that
will only convert values if it is set (if it says that the system is big
endian). Detecting whether the system is big endian is also somewhat difficult
as most operations masquerade the endian-ness of the system such that they will
behave the same on a big endian or little endian system. For example, on a
little endian system a bit shift to the left of the number 128 will give the
same result as the same bit shift on a big endian system:
Little endian: Shifting (128) 10000000 00000000 will result in 00000000
00000001 (256)
Big endian: Shifting (128) 00000000 10000000 will result in 00000001 00000000
(256)
So to check if the system is big endian you have to use a lower level construct
available from C. A union of a 32 bit integer and an array of structs does the
trick. The following code is used to check at runtime if the system is big
endian or little endian so that the flag can be set appropriately to convert all
numbers before writing them to the bitmap file.
union testdata
{
char arr[4];
int32_t data;
}
tdata;
char
c='\0';
for (int
i=0;i<4;i++)
{
tdata.arr[i]=c++;
}
if ( tdata.data == 0x00010203
)
bigEndian=true;
else
bigEndian=false;
As a result of this check, the bitmap writer will work on little and big endian
systems and it is a very small and concise class.
Writing an XML reader
The XML reading library we used, libxml++, was also not available on the
playstation 3. This meant that we had to write our own XML reader. Fortunately
the reader we used from the library was well-defined and concise, writing our
own that used the same implementation wasn't too difficult. The XML reader
aligns to one tag in the XML file at a time - this is either an actual XML tag
or a text node between XML tags. At any point, the program can query the XML
reader as to the current tag's attributes, name, and depth in terms of how many
tags it is nested inside of. We used the exact method names and parameters as
from the libxml++ library such that converting it over was a matter of
instantiating our own xml class instead of the libxml++ one. The resulting XML
reader was also much smaller than the external library.
Issues porting to the lower SPE cores
At this point, compiling the ray-tracer and running it on the upper PPU core
worked, but the key to parallelization on the system is to run your code on the
lower SPE cores (of which there are 8 on the playstation 3). However, these
cores were not meant for large programs. Most parallelization is done by finding
small portions of code which can be farmed off to the SPE's, however the
greatest gains can be made by having the lower cores do as much of the work as
possible. Doing so also reduces the communication overhead required and a
ray-tracer has completely independent pixels so the rendering can be divided
between screen pixels. To keep the design simple we decided to let each of the
cores read the XML file, and they would each render a block of the image and
these blocks would be combined to form the overall image. This decision also had
to weight the overhead of performing DMA transfers for each object, versus the
overhead of the I/O on each SPE. The individual SPE's do not natively perform
I/O, instead every I/O call is sent to the PPU to perform the actual
functionality. This generates significant overhead, as the PPU must handle all
of the context switching. Even with this added overhead it was deemed acceptable
because the overhead required to generate and transfer the complete data
structure to the cores would have been larger.
Executable code size
The main problem we had through was to get the executable size small enough to
be able to run on an SPE core. Initially the compiler would not allow us to
compile more than a single or a few classes. We had already eliminated any large
external libraries so the next step was to remove some of the STL (C++ Standard
Template Library) classes. We rewrote the functionality of an STL vector, and
implemented our own map. With the code size still too large we had to remove all
string's in the code and replace them with character arrays and the relevant
string functions from the standard C libraries. After having removed all of the
STL classes in use, the code was finally small enough to compile for the
playstation SPE cores.
Delayed Memory Access
The next issue we ran into was rather difficult to track down. Runtime memory
allocation and loading of the variable to the local store were done as separate
actions. Due to this, it would often take time before the initialized value made
it to memory and then back to the local store. This occurred only on the initial
initialization, afterwards, with the variable loaded into the SPE Local Store,
all storing and access of variables had no delays. We had to place a few busy
loops in the XML reader to wait for the memory to become initialized when
reading the XML file so that it would be ready to be read for the classes using
the XML reader immediately after calling read. For an example see the following
code:
attrname=(char*)malloc(sizeof(char)*6);
strcpy(attrname,
"value");
while(attrname[0]=='\0');
Without the delay above the attribute name would still be uninitialized when it
was checked later and the results of loading the XML file would be incorrect.
This defect was initially discovered when working with the DMA transfers between
the PPU and the SPUs. The standard call for fetching data from the PPU, mfc_get,
does not natively block on the PS3. So data loaded from the PPUs encountered the
same error as above. When this first surfaced the above malloc issue had not yet
been encountered, so even though the cause had been determined for the DMA, it
also occurring for malloc was not known. Methods to resolve this lack of
blocking are very poorly documented, through testing it was found that two
method calls, placed after the actual DMA call would block, resolving this
issue:
mfc_write_tag_mask(1<<tag_id);
mfc_read_tag_status_all();
Methods of Offloading
One of the most
significant portions of coding for the Cell Broadband Engine Architecture is
determining the most appropriate offloading methods. Since we were porting the
raytracer instead of creating one
from scratch, it meant
that the structure would be very intertwined and that this would be an issue. As
discussed above, the location for file I/O to be called, was a major factor in
the design of the offloading. In addition to the overhead concerns, there was
one other issue. The actual file loading was distributed throughout
the class structure. This further
encouraged our choice of including it within the code to be offloaded to the
SPEs.
Furthermore there were two main choices regarding the subdivision of workload.
The first was the subdivision of rendering. Initial issues with the setup
of DMA transfers encouraged us to adopt an early method of offloading to the
SPE's one line at a time. Having to create and offload to each SPE for every
line created a large overhead that was deemed too detrimental. The next attempt
was subdividing the screen, but once again troubles with DMA forced us to use a
temporary solution of saving to the bitmap from the SPE's. As previously
mentioned, the actual file I/O still occurs at the level of PPU. Benchmarking of
this showed that the file writing actually took 6.0 to 6.1 seconds to process.
Once again unacceptable.
The final method of offloading came about once the troubles with DMA transfers
were resolved. The final structure has the SPE's each responsible for rendering
one chunk of the scene. Each SPE renders one line of pixels at a time, then
sends all of those values to the main memory of the PPU. Then upon the
completion of the execution of all threads, the file saving is done all at once.
With the file writing occurring at the level of the PPU, there is no overhead
caused by context switching, this allows it to occur extremely quickly. Using
the same file to benchmark, the complete processing time was reduced from 6
seconds to 0.7 seconds.
Vectorization
One of the most significant performance gains
of the PlayStation3 is the fact that the processors are vector based. The vector
structure and functionality is based on Altivec standard for PowerPC derived
architecture. On the PPU the actual Altivec library is used, while on the SPE's
an spu_intrinsics library provides 1-for-1 implementation of the Altivec set for
use on the SPE's.
The central concept behind vectorization is the ability to be able to do
multiple math calculations in one instruction set. Each vector holds 4 values,
standardly unsigned integers or floats. The speed for double precision
calculations on the PS3 are standardly deemed too slow. For this reason single
floating point math is standardly done, with additional instructions to be able
to simulate double precision using two separate single precision floats. Since
the vector holds four values, when math functions are performed on vectors it
allows for four simultaneous calculations. These calculations are done matching
indices, where element one from one vector will be calculated with element one
from the second vector.
Being able to parallelize not only the actual rendering of the scene, but to be
able to further parallelize the process by focusing on the actual arithmetic,
presents the ability to get great speed gains. In the raytracer, all applicable
math located within the point class was converted into vectors to allow for the
most performance gain. Initial tests of this presented significant results.
Using a scene that had a know file I/O time of .3s, and whose total runtime was
.7s, after vectorization this time was reduced to .6s. This was a speed gain of
25% where both the pre and post vectorizations were the average values of
approximately 20 runs of each method. Larger scenes also demonstrated a
significant gain thanks to this conversion.
Extra Features
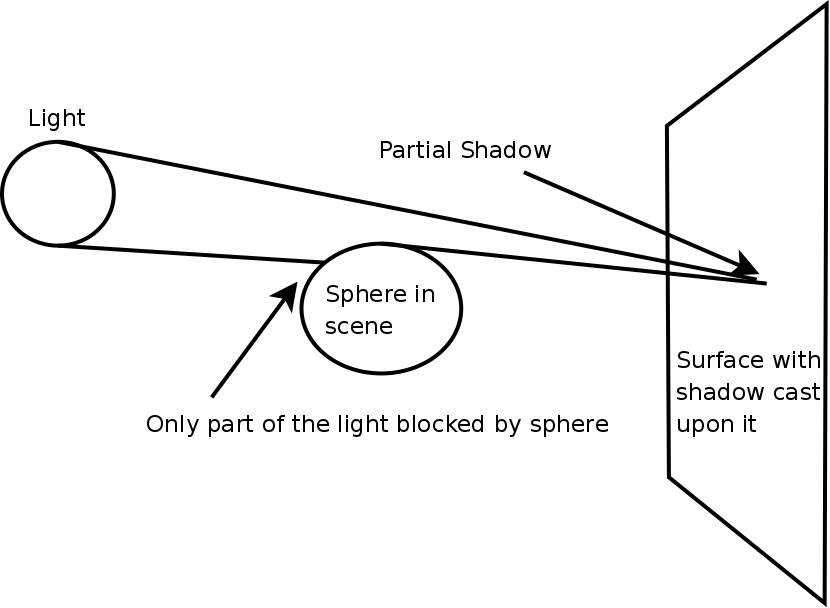
Soft Shadows for Spheres
One special feature we added over the ray-tracer used from class was the
implementation of soft shadows. They have been implemented as an optional radius
attribute for lights. The theory behind the soft shadows implemented is simple.
Light's in real life usually do not come from point sources so much as an area
or surface. Or, while the light itself may come from a point source we often
place a spherical bulb around it that essentially acts like a new transmission
source for the light. As a result, partial shadows will occur when part of that
bulb is blocked but part of it is not.
In the ray-tracer, we calculate this percentage of light by imaging a light as a
sphere and when trying to light a point we cast a cone to that point. During
intersections with objects we determine the percentage of that sphere which is
blocked and remove that much of the light. This results in objects which are
closer to the surface having a finer sharper shadow (due to being at the small
part of the cone) and objects which are further away giving a softer shadow (as
the cone is wider passing the object). Determining this percentage of the cone
which is not blocked for spheres was easy, but this is not the case with
triangles and other more complex objects. As such, we have only implemented soft
shadows for spheres at present. The result of such a soft shadow calculation can
be seen in the following image.

You can see the shadows get softer as the object is further from the surface
cast upon or closer to the light.
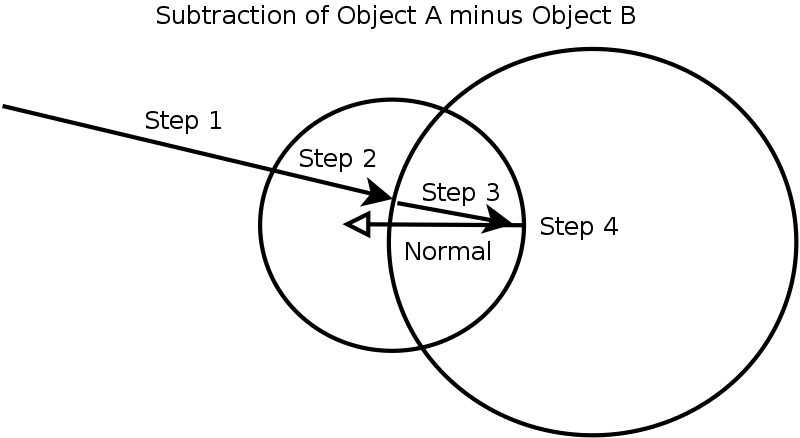
Constructive Solid Geometry
Another feature of the ray-tracer is the creation of CSG objects. The idea is to
construct an object from the extents of two solid 3D objects. The various means
of construction are subtraction, intersection, and union. The result of a
subtraction of object A minus object B exists in space where object A exists but
not object B. The resulting object from an intersection only exists where both
of the objects involved exist. The result of a union is probably the most
subtle, but it exists where either object A or object B exists, and has no
interior surfaces for things like refraction. The implementation is relatively
simple and as XML is used for the input language the two objects involved can be
nested inside the compound object's tag.
New intersection algorithm for subtraction of object A minus object B (If the
origin of the ray is inside object A start with step 3):
-
Find next intersection with object A (If none found then return with no
intersection).
-
If not inside object B, return with intersection point and normal from
object A. Otherwise, continue.
-
Find next intersection with object B.
-
If still inside object A, return with intersection point and the opposite
normal of hit on object B. Otherwise, continue with step 1.

Example of a subtraction boolean operation.
New intersection algorithm for intersection of object A and object B:
-
Find next closest intersection with object A or object B (If neither have
intersections, then return with no intersection).
-
If inside object A and object B, return with intersection point and normal
from intersection object.
-
Otherwise, go back to step 1.
New intersection algorithm for union of object A and object B:
-
Find next closest intersection with object A or object B (If neither have
intersections, then return with no intersection).
-
If not inside the other object, return with intersection point and normal
from intersection object.
-
Otherwise, go back to step 1.
Benchmarks
To test the final raytracer and in order to get proper comparisons with the
original raytracer we performed a series of benchmarks. Various input files were
ran on the appropriate following versions and platforms: Non-threaded and
threaded on an Intel Core Duo, threaded on the PlayStation3 and threaded on
Sandcastle.
objects.xml

lens.xml
File
|
Robert's Laptop - Non-Threade
|
Robert's Laptop - Threaded
|
Playstation 3
|
Sandcastle (8 cores)
|
objects.xml
|
0.760s
|
0.413s
|
0.692s
|
0.15s
|
lens.xml
|
4.692s
|
2.540s
|
2.882s
|
0.62s
|
mirror.xml
|
5.500s
|
2.952s
|
(Broken due to SPE memory issue)
|
0.70s
|
Back to COSC 4P98 Projects